Quality requires visibility. You cannot fix — or even trust — what you cannot see. That’s true in any project, but it becomes even more urgent when the team doing the work is a software factory and you’re not reading every line of code.
When I’m not micro-managing the implementation, the thing I’m actually managing is my own insight: the gap between what the system was intended to do and what it’s actually doing. So let’s go over a little bit of what I’ve done to ensure I’ve got the visibility I need to ship a robust experience while using unreliable coding agents to do the heavy lifting.
Apparently I’m doing a series of blog posts about this project!
Part 1: Six Days Equals Six Weeks
Part 2: Specialists in the Factory
Part 3: The Invisible Work Matters
Part 4: Progress, 37 Days in
Part 5: The Meta-Game Begins
Part 6: In Which I Intervene in the Code
Part 8: Roost, Terrain, and Sound
Intention vs. reality
You ask the robot to build a feature. It files a PR. You check out the PR, run the code, and it seems to work. Awesome!
You have another robot double-check things. Are the tests trash? Is performance going to be an issue? Is there an attackable surface being touched (and if so, does this weaken our security posture)?
The second robot finds a few minor things. This is always more reassuring than when it finds nothing. The first robot fixes those things, and the second robot gives the all clear.
The tests pass. The linters are quiet. Everything’s good, right?
Maybe. But… are you sure? How do you know? Software complexity ramps up sharply as the number of moving parts increases.
Even setting aside the possibility of regressions, there’s the problem of all the locally-relevant complications you failed to think of.
Making the runtime tell on itself
My approach to this problem has been multi-layered:
- Multi-layered code review processes. As described in the initial blog post. This has found a bunch of issues early, but it’s far from complete.
- Code audits (also part of the early process definition!), feeding iterative refinement of architecture and practices, with associated refactoring. I have spent a bunch of time having the robot refactor code to normalize deviating patterns and keep things easier to reason about and reduce the number of places in the code that need to be fixed when a problem emerges. The network code is the most recent such subsystem. It had begun to grow a little too organically, with UI actions kicking off network operations directly, multiple separate store-and-forward implementations, multiple places in the code caching the same server-provided data independently, etc.
- Visibility, visibility, and more visibility.
That third point is what I want to talk about, because in the context of a mobile game, that gets a bit more complicated than you might expect.
The visibility concern also features multiple layers of implementation.
Layer 1: Build-time validations
There is a lot of code that verifies that scene objects / prefabs / assets are wired properly. A broken reference can lead to some truly wonky runtime problems. With Hordes of Orcs 2, I had a demo build I was showing at MacWorld where upgrading the ice tower to level 4 (IIRC) would result in… no tower. The tower was there, and it was firing you just couldn’t see it. A reference to the mesh had gotten broken somehow. This layer helps mitigate the risk of issues like that.
Layer 2: Assertions
Claude loves to write defensive code. Lots of runtime checks. Where possible, I’ve forced it to refactor as much of that as possible to being build-time validations. Where that’s not a strong enough guard, I’m favoring not doing explicit checks and letting things just throw uncaught exceptions of the assumption breaks. If that’s not good enough, explicit Debug.LogError is a great way to ensure an error is logged with whatever context might be relevant.
Of course, that’s all well and good when I’m running the game on my machine. But I’m never going to stress every possible codepath.
That brings me to…
Layer 3: Telemetry
Of course the usual suspects show up here. DataDog, Sentry, etc. But that doesn’t really help me with client issues.
So, a while back I added a log interceptor that keeps a ring buffer of Unity log messages, and when an error message is occurred sends the buffer, and a bunch of game state, to the server. That state includes things like the kind / position / orientation of every orc in play, information about every tower, etc.
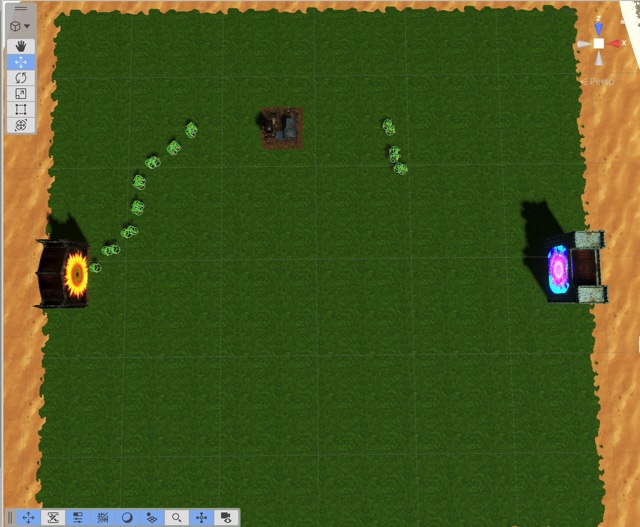
The image at the top of the blog is a reconstruction of the game state of a player who accidentally found a pathfinding bug.
Claude came up with several hypotheses based on the initial description I gave it – that a orc had tripped its onUnreachable component despite there not being a construction of towers that could conceivably block it. It did, in fact, find a couple bugs – one of which I could actually reproduce given its instructions.
Seeing the board, however, told me something crucial: The bugs it found? Not the bug the player hit. (Still digging into that one!)
Bit by bit, I’m building up a richer telemetry system, and supporting tooling for Unity to help me understand the data the client is feeding me.
But wait! There’s more!
Layer 4: Measuring the factory
If you’ve read the rest of this series, you’ve watched as I’ve evolved the process bit by bit. Doing that requires inight into how effective the process is. That means keeping track of recurring failure modes, identifying when I’m unconsciously adapting to quirks of the tools, and so forth. Where possible, I’m quantifying that using Github issue labels. In particular, Regression. I even have charts!
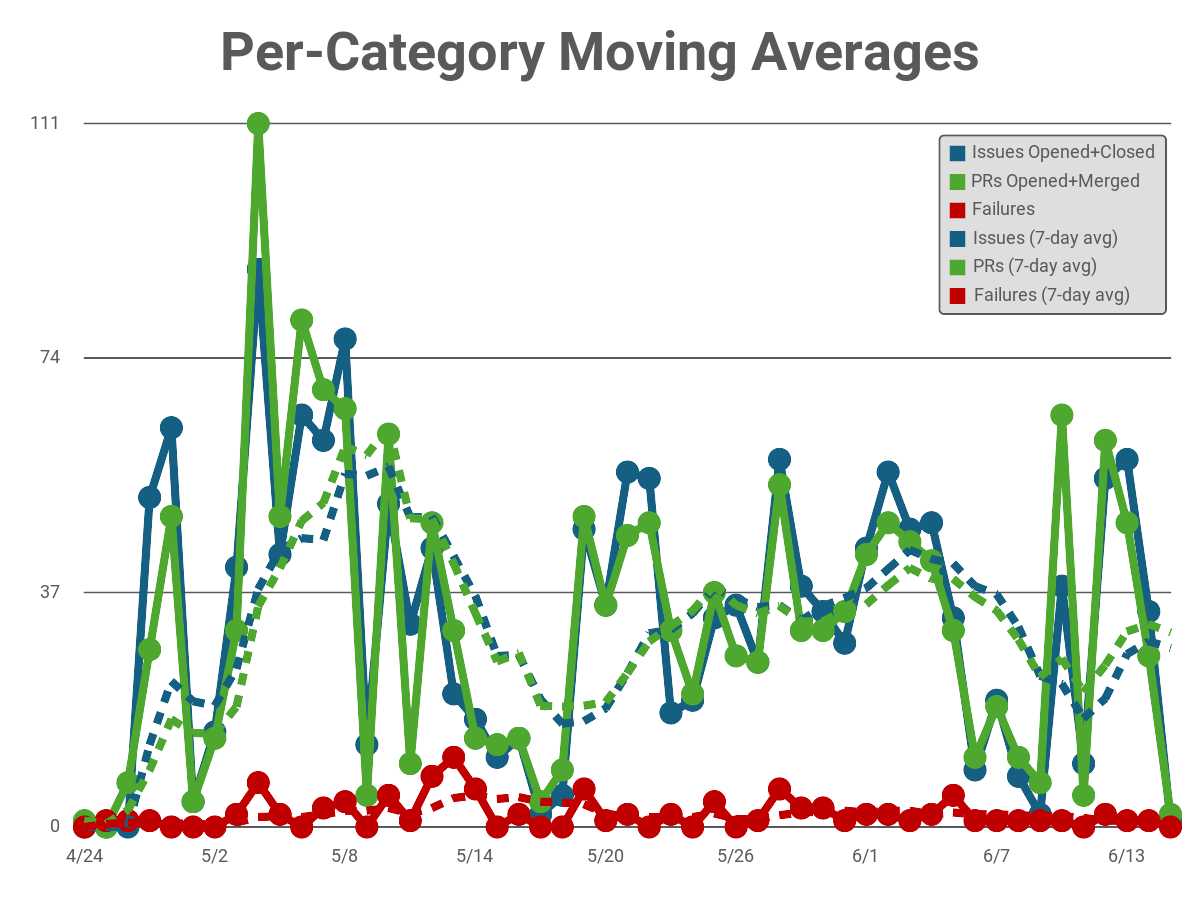
That chart is built, and maintained via a very simple tool:
rake github:export github:report
Where this leaves me
Right now, the project is approaching a key inflection point. The next build ships a few major things:
- The infrastructure for localization (with two real, and one jokey locales)
- Google OAuth sign-in to let you play across devices (plus the infrastructure for Apple sign-in)
- A major refactor of the networking and state management infrastructure
The total fundamental complexity of the systems are beginning to add up. It’s no longer just “place towers, towers shoot at orcs”. There’s a persistent datastore, and cross-device synchronization, and all the security and correctness issues that implies. And everything that happens after this release will be made more complicated by needing to fit in with it.
Managing quality is going to get harder from here on out. I’m fascinated to see how this plays out and what I need to do to keep things on track.